前面一篇聊了一些基础的概念,在这篇里可以试一下基础的搜索和收集内容。
当我们在用百度搜索时,我们会看到很多相关的信息。于是我们可以用爬虫来帮助我们搜索和收集相关的信息。
比如我想查看百度收录的stackoverflow里爬虫相关的内容的前十条,打开浏览器比如firefox或chrome,按F12打开dev tool,再输入百度的地址访问并搜索时,在network tab下我们能看到请求的详细信息,如下图。当了解了这个过程和一些参数,我们便可以模拟这个过程。
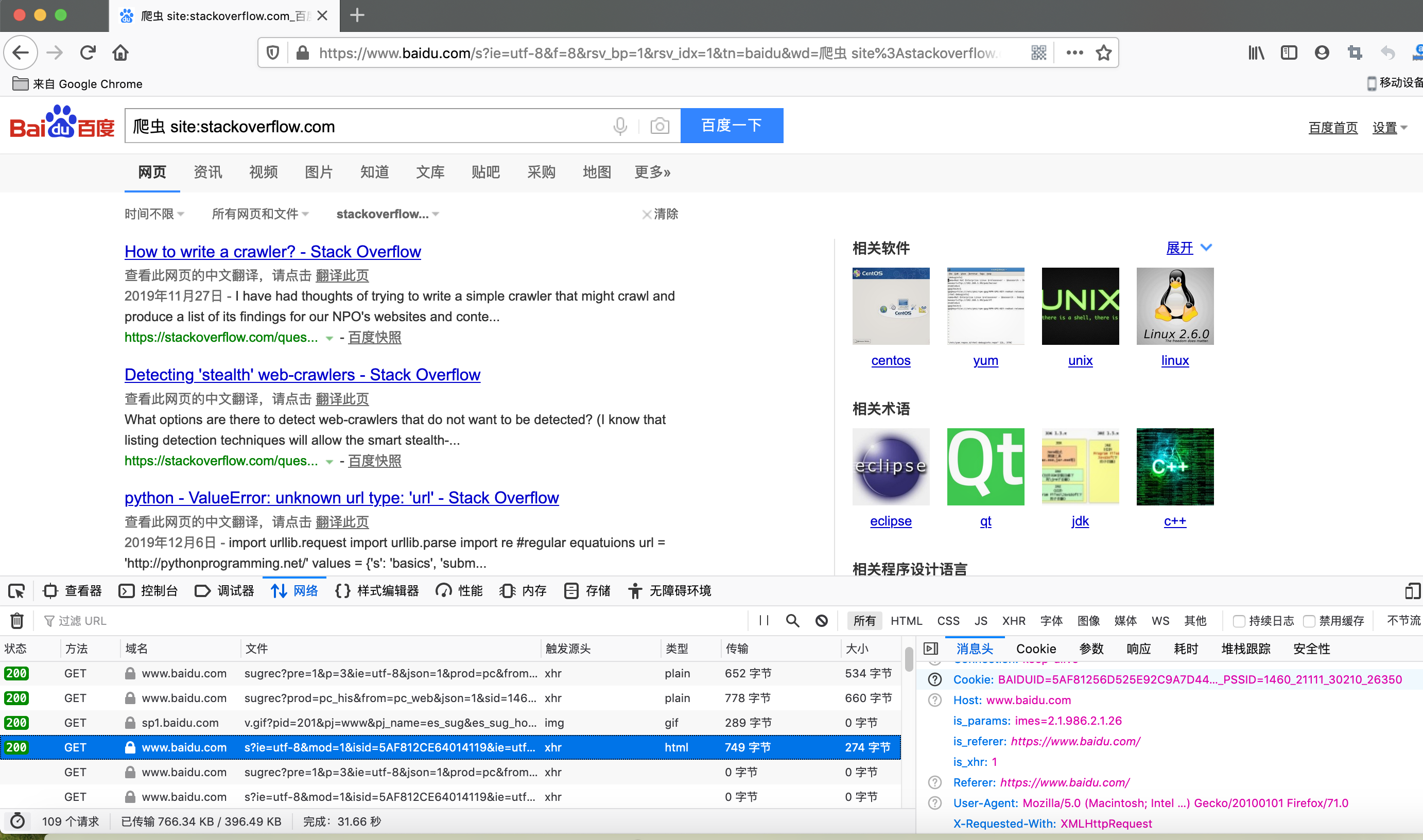
首先我们先用requests库来封装一下http的get。
# in utils
import requests
class HttpHelper:
default_headers = {"Content-type": "text/html; charset=UTF-8"}
@classmethod
def get_response_by_url(cls, url, data=None, headers={}):
headers = dict(cls.default_headers, **headers)
if data:
result = requests.get(url, headers=headers, params=data)
else:
result = requests.get(url, headers=headers)
return result
前面看到当我们搜索后的地址很长,是
"https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E7%88%AC%E8%99%AB%20site%3Astackoverflow.com&rsv_pq=e46a4ffd003d9ffd&rsv_t=b750PbHmT1mgiHfW6V8XLz6XgZ4BNsjAOvxidQN%2FXv%2BmzkQDG%2B%2BL%2B7lxyUo&rqlang=cn&rsv_enter=1&rsv_dl=ib&rsv_sug3=38&rsv_sug1=9&rsv_sug7=101&rsv_sug2=0&inputT=10432&rsv_sug4=13294"
我们实际用不了那么多的参数。比如我们的关键词是: 爬虫和stackoverflow,只要找到这两个关键词,把其他无关的去掉,那么url就变成了
"https://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB%20site%3Astackoverflow.com"
我们干脆也装成用firefox来访问(当然加这个并不能欺骗服务器,很容易被排查出来。完全伪装则放在后面讲),并把返回的内容转成中文编码,再存储到文件里看看。如下。
# -*- coding: utf-8 -*-
url = "https://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB%20site%3Astackoverflow.com"
additional_header = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"} # 把firefox的agent换进去
response = HttpHelper.get_response_by_url(url, data=None, headers=additional_header)
print(response.status_code) # 得到状态码200,表示获取成功
with open("./temp/baidu.html", "w") as f:
f.write(response.content.decode('utf-8')) # 存储内容
打开保存的文件,会发现只包含了html,没有样式,因为没有请求其他文件。
另外如果想获得更多的结果怎么办?其实类似我们去点击下一页一样。我们看到url有变化,多了&pn=10. 这个就是进入下一页的意思,因为百度默认一页展示10个结果。如果我们设置pn=2,那么第一页展示的结果就会从第三个开始。
我们通过设置不同的url就能获取不同的展示结果。我们还可以通过解析返回数据是否包含下一页,来设定循环获取所有结果。对于一些会返回json数据包含了长度的,那么就更方便了。
接下来我们就需要解析文件,获得我们想要的信息。放在下一篇讲。
相关代码会放在https://github.com/bobjiangps/python-spider-example
文章评论 (0)