对于很多网站来说,登录后才会呈现部分数据。对于非网页形式的服务端,用户身份验证也是必要的操作。
比如贴吧登录后才能看到我的收藏,比如只有有妖气会员才能看的收费漫画,等等。
于是爬虫也需要能够模拟用户登录的行为,才能获取需要的数据。
关键是在能获得服务器认可的已登录状态。而服务器看的要么是cookie,要么是token。cookie和token都是服务器赋予客户端的一个身份验证,只是管理的策略不一样。而我们手动操作的登录也就是用账号密码去服务器请求一个身份验证,下一次操作就带着这个身份验证去服务器那里获取数据。
综上所述:
1. 当我们已经有cookie或token时,直接传递给服务器即可。不过需要注意cookie和token都是有过期时间的。
比如打开微博朋友的粉丝列表,传递自己的账号cookie。
import requests
if __name__ == "__main__":
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:73.0) Gecko/20100101 Firefox/73.0',
'Connection': 'keep-alive',
'cookie': 'replace your cookie here' # update text
}
session = requests.Session()
response = session.get('https://weibo.com/2671109275/fans?rightmod=1&wvr=6', headers=headers)
print(response.text)
print(response.status_code)
cookie的值可以在浏览器的devtool下看到,例如下图:

我没有细找使用token的网站,token的部分便用自己的本地服务器代替。
import requests
import json
if __name__ == "__main__":
url = "http://127.0.0.1:8000/automation/api/login/"
user_info = {"username": "Basic",
"password": "test1234"}
response = requests.post(url, data=user_info)
print(response.status_code)
server_user_data = json.loads(response.text)
print(server_user_data)
print(server_user_data["token"])
结果如下图,后续便可传递这个token来获得权限。

2. 当我们没有cookie或token,或者已经过期无法使用了,那么我们就需要模拟登录重新获取了。可以是用requests提交表单,也可以是用selenium模拟真实操作。
2.1 使用Selenium
和前面文章描述的selenium用法一样,用不用headless就看自己。如下代码所示,输入账号密码成功登录后获取cookie。
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import getpass
class CustomizedWait(WebDriverWait):
def wait_until_presence_of_element(self, by, value):
return self.until(EC.presence_of_element_located((by, value)), "fail to wait until presence")
def wait_until_visibility_of_element(self, by, value):
return self.until(EC.visibility_of_element_located((by, value)), "fail to wait until visibility")
def login(dr, name, pwd):
user_input = dr.find_element(By.ID, "loginname")
pwd_input = dr.find_element(By.NAME, "password")
login_button = dr.find_element(By.XPATH, "//div[@class='info_list login_btn']/a")
user_input.send_keys(name)
pwd_input.send_keys(pwd)
login_button.click()
if __name__ == "__main__":
user_name = input("input user name:\n")
password = getpass.getpass("input password:\n")
url = "https://weibo.com/"
driver = webdriver.Chrome()
driver.get(url)
cw = CustomizedWait(driver, 30)
cw.wait_until_presence_of_element("id", "loginname")
login(driver, user_name, password)
cw.wait_until_presence_of_element("xpath", "//ul[@class='gn_nav_list']//a[@class='gn_name']")
cookie = [item["name"] + "=" + item["value"] for item in driver.get_cookies()]
print(cookie)
driver.quit()
2.1 使用requests
首先需要知道是发送数据给哪个地址。
还是手动操作并用devtool监控,并勾选preserve log以避免页面跳转丢失请求列表。如下图。
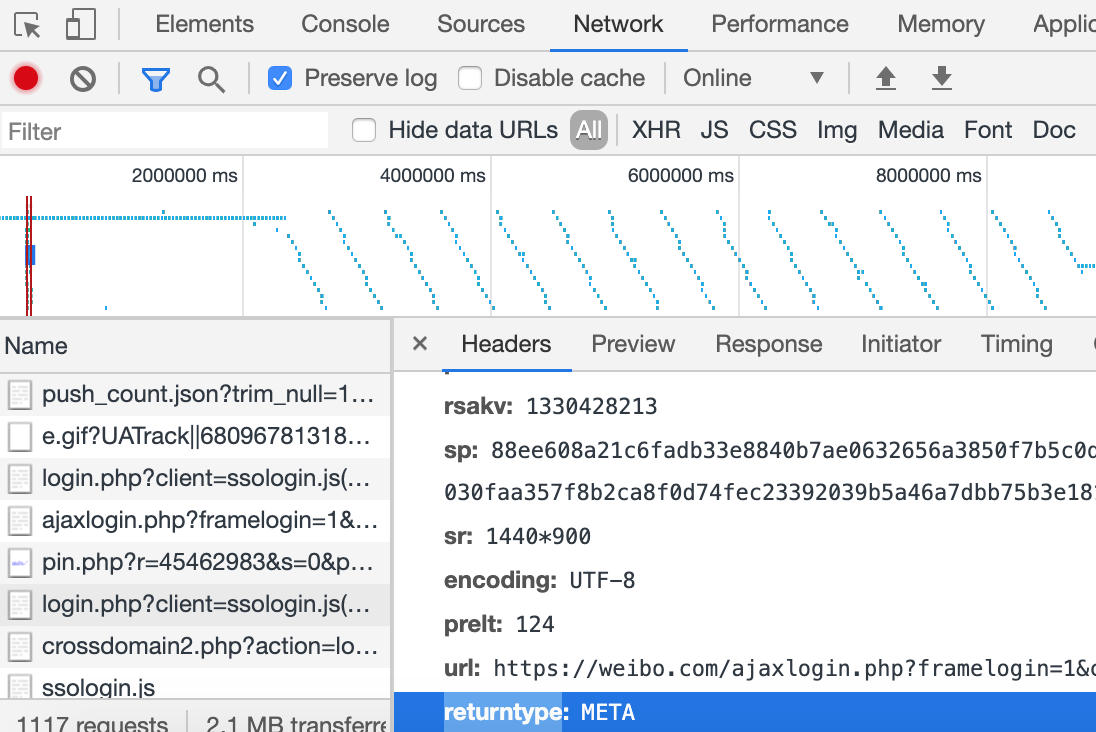
不过用requests post数据过去产生了错误,等后续解决后再来更新这部分的代码样例。
文章评论 (1)
谢谢分享,解决了我的问题!!